
Vamos a explicarte cómo entrenar a una IA con tu cara para generar tus propios avatares e imágenes personalizadas. Concretamente, lo que haremos es entrenar a Stable Diffusion por nuestra cuenta para que nos conozca, y luego utilizar esta popular IA para generar imágenes con nuestra cara.
El conseguir resultados como los avatares de Lensa dependerá de la paciencia que le dediquemos luego a explorar los comandos escritos que podemos pedirle a la IA para generar los avatares. Sin embargo, el primer paso es el que te diremos de una manera detallada, y luego ya todo dependerá de ti y de tu pericia.
Realmente, este proceso es más sencillo de lo que parece, aunque puede tardar horas en hacer el aprendizaje, ya que se basa en cuadernos de entrenamiento creados por personas para que tú solo tengas que cambiar algunos parámetros. Pero claro, la primera vez que entramos en uno de ellos puede que nos intimide ver tanta cosa extraña, por lo que vamos a intentar explicarte el proceso de una manera que puedas entender.
Vamos a empezar explicándote un poco los conceptos básicos de lo que vamos a hacer, de forma que entiendas por qué hay varios procedimientos para hacer lo mismo. Y luego, pasaremos a decirte todo el proceso en varios pasos, desde la selección de las fotos a utilizar hasta el entrenamiento de la IA y luego su utilización.
Algunas cosas antes de empezar
Antes de empezar com el proceso, debes saber que hay varias maneras de hacer esto, tanto el entrenamiento de modelo de IA para aprender a usar tu cara hasta luego su utilización dentro de Stable Diffusion. Nosotros, vamos a utilizar los modelos del proyecto Fast Stable Diffusion, tanto para el entrenamiento como para montar luego Stable Diffusion, puesto que es uno de los métodos más sencillos y recomendados por expertos en materia de IA.
Para democratizar estos procesos, los desarrolladores y expertos en Inteligencia Artificial crean los denominados cuadernos en la plataforma Google Colab. Se trata de una plataforma que te permite programar y ejecutar código Python, y compartir tus creaciones con otros usuarios. Con estos cuadernos podrás usar una GPU virtual para los procesos que es limitada cada día, pero que es suficiente para entrenar tu modelo de IA y usarlo durante una o dos horas.
Entonces, lo que vamos a hacer hoy es utilizar dos de estos cuadernos para entrenar la IA y usar el resultado en Stable Diffusion. Para ambos pasos, tienes varios tipos de cuadernos con pasos diferentes y formas diferentes de proceder, pero yo te voy a proponer el que yo he utilizado personalmente. Luego, una vez domines estos pasos iniciales ya podrás aventurarte a buscar otros cuadernos con otros procedimientos.
Para entrenar a la IA primero vas a necesitar tener preparada una serie de fotografías de tu cara, ya te lo especificaremos en el primer paso. Además, estos cuadernos se van a ejecutar utilizando memoria de tu Google Drive, por lo que también necesitarás tener al menos 4 GB libres de almacenamiento en la nube de Google.
Lo que vamos a hacer nosotros es entrenar a la IA con nuestras fotos utilizando el modelo de generación de aprendizaje Dreambooth a través de un cuaderno. El resultado será un archivo donde podríamos decir que está «lo aprendido». Y luego, usaremos el cuaderno de AUTOMATIC1111 para instalar Stable Diffusion en Google Drive, moveremos el archivo de aprendizaje de la carpeta donde se ha creado a la de SD, y luego ejecutaremos la interfaz web para empezar a generar las imágenes.
Estas herramientas que vamos a utilizar tienen múltiples opciones para entrenar tus modelos de distintas maneras y usar diferentes versiones de Dreambooth. Nosotros no vamos a centrar en el proceso más básico y sencillo, que sea un punto desde el que dar los primeros pasos.
Primero, tienes que elegir tus fotos
Lo primero que tienes que hacer es elegir las fotografías que vas a querer usar para entrenar a la IA con tu cara. Esto es lo que se denomina el dataset, la colección de datos que vamos a utilizar para alimentar a los algoritmos de la inteligencia artificial para que aprenda las características de nuestra cara y sea capaz de definirlas.
Lo ideal es que crees una carpeta para esto en tu ordenador y guardes en ella unas 30 fotos tuyas. Yo he usado algunas menos, pero lo recomendado para entrenar la IA son 30 fotos, o sea que con ellas tendrás unos mejores resultados.Deben ser fotografías en los que solo aparezcas tú, no debería aparecer ninguna otra persona ni animal junto a ti.
Sobre qué tipo de fotos debes utilizar, lo más importante es que la mayoría de ellas sean de tu cara, primeros planos o fotos que se te vea básicamente solo la cabeza. Para entrenar mejor a la IA, también puedes incluir algunas fotografías de medio cuerpo, y quizá incluso también alguna de cuerpo entero. Pero lo principal es que la mayoría sean de tu cara.
Por último, para optimizar el entrenamiento es recomendable recortar las fotos para que todas sean cuadradas, preferiblemente en un tamaño de 768×768. En el caso de que tuvieras alguna fotografía que aparezca una segunda cara junto a ti, puedes intentar borrarla tapándola con color blanco aprovechando la edición. Además, esas pocas de cuerpo entero, si son fotos verticales, puedes editarlas cuadradas añadiendo blanco a los lados.
En cualquier caso, presta cuidado a la hora de crear tu dataset de fotos propias para entrenar a la IA. Y recuerda guardar esta colección en una carpeta aparte, ya que siempre vas a poder volver a recurrir a ellas para entrenar otra vez la IA desde cero usando las mismas fotos.
También debes ponerles a todas las fotos un mismo nombre, con un número entre paréntesis para diferenciarlas. El nombre que debes ponerlas es ese nombre que quieras luego usar en los comandos o input de la inteligencia artificial para referirte a ti. Si le llamo a mis fotos yubal, luego tendré que decirle a la IA que haga fotos de yubal de determinada manera.
Empieza con el cuaderno de entrenamiento
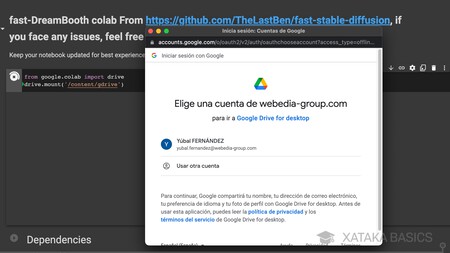
Ahora, tienes que entrar en la página de Google Colab de Fast DreamBooth, donde está el cuaderno de entrenamiento automatic1111 que vamos a utilizar. En esta página, arriba del todo tienes un bloque from google.colab import drive, y cuando pases el ratón sobre él tendrás un icono de reproducción sobre el que tienes que pulsar para lanzarlo.
drive.mount('/content/gdrive')
Al hacerlo te aparecerá una advertencia, y al aceptarla procederás a vincular el cuaderno con tu cuenta de Google Drive. Tienes que iniciar sesión y aceptar el procedimiento dándole todos los permisos para conectarse a tu Google Drive. Cuando termine, deberá aparecerte el texto Mounted at /content/gdrive debajo indicándote que se ha montado este modelo en tu cuenta de Google Drive.
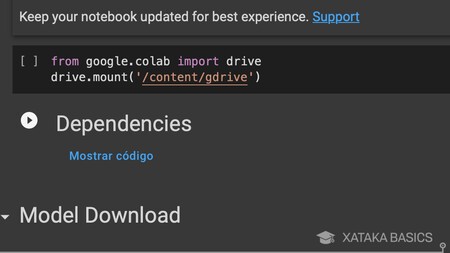
A continuación, tienes que hacer lo mismo y ejecutar el elemento de Dependencies que te aparecerá en segundo lugar. Esto va a instalar las dependencias necesarias en tu cuenta de Google Drive. Este proceso solo durará unos pocos segundos.
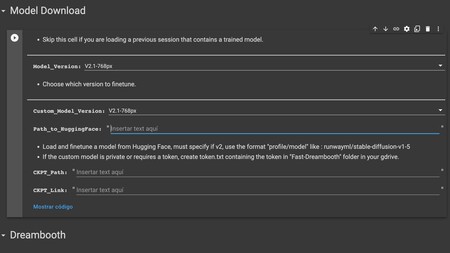
Ahora toca pasar al bloque de Model Download, que es uno de los pasos más importantes. Aquí, lo que tienes que hacer es desplegar las pestañas de Model_Version y Custom_Model_Version, y en ambos casos eligiendo la v2.1-768px.
Como ves, puedes elegir entre 768px y 512px, pero si has editado las fotos de tu dataset a 768×768 píxeles, debes usar la 768px. Cabe la posibilidad de usar fotos a 512×512, pero la recomendada es la de 768px para tener mejores resultados. Espera unos segundos hasta que aparezca Done! abajo en verde, indicándote que se ha cargado este bloque.
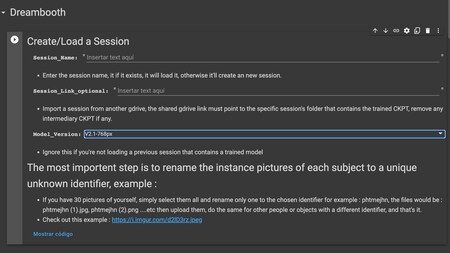
Ahora vamos al bloque de Dreambooth, que está dividido en varias celdas ejecutables, siendo la primera la Create/Load a Session. Tienevarias cosas que puedes rellenar, de las cuales no todas son importantes. Realmente, solo es suficiente con rellenar Model_Version, pero aunque los dos elementos anteriores no son necesarios para el procedimiento sencillo, vamos a explicártelos igualmente.
Session_Name: Puedes crear una sesión poniéndole un nombre. De esta manera, si no te gusta cómo se ha entrenado una IA, puedes añadir más pasos a la sesión en vez de empezar desde cero. Pero la primera vez que uses esto no hace falta poner nada ni rellenarlo. Esto es solo si trabajas con varias sesiones.Session_Link_optional: En el caso de que no uses Google Drive sino que hayas creado una IA en otra cuenta, puedes añadir su enlace aquí. Pero ahora, no hace falta poner nada.Model_Version: De nuevo tienes que indicar el nombre de la sesión. Tiene que ser el mismo que hemos usado en el paso anterior.

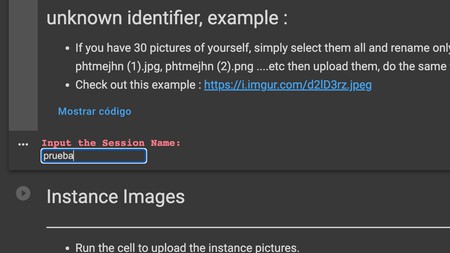
Cuando termines con todo, ejecuta la celda Create/Load a Session con el botón de reproducción que hay a la izquierda del titular del cuadro. Si has dejado los dos primeros libres, te pedirá escribir un nombre de sesión en un texto en rojo, y puedes escribir el que quieras, como prueba. Generará una sesión, y cuando termine sigue con el paso siguiente.
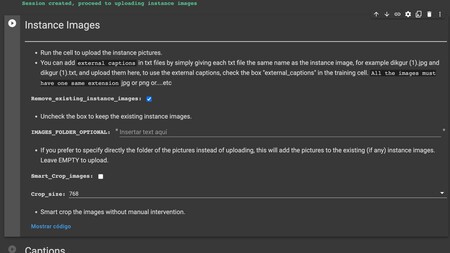
Ahora, vamos con la celda de Instance Images. Estas son las diferentes cosas que debes anotar o cambiar antes de ejecutar el elemento, te las explicamos una a una. Y cuando lo tengas, puedes ejecutar la celda.
Remove_existing_instance_images: Elimina las fotos que estuvieras usando en otras sesiones. Si es la primera vez que haces esto, déjalo como está.IMAGES_FOLDER_OPTIONAL: Si quieres, te meterá tus fotos en una carpeta que le digas que cree. No hace falta poner nada:Smart_Crop_images: En el caso de que no recortaras las imágenes ni les cambiaras el tamaño como te hemos dicho antes, con este campo puedes pedir que se haga automáticamente. Sin embargo, lo recomendado es hacerlo tú a mano para asegurarte de que queden bien recortadas.Crop_size: En el caso de que vayas a recortarlas o cambiarles el tamaño, aquí puedes elegir cuál utilizar. Pero en este caso, habiendo hecho el trabajo antes no hace falta que las pongamos a 768 con este método.
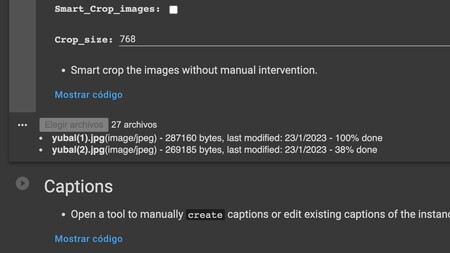
Cuando ejecutes esta celda, abajo del todo te aparecerá la opción de seleccionar archivos abriendo un explorador de archivos. Con ella, tienes que elegir y añadir las fotos que hemos preparado al principio de todo. El proceso de subida tardará unos minutos, y dependerá de tu conexión a Internet.
En los siguientes dos puntos, Captions solo lo tienes que ejecutar tal y como está, y el siguiente te lo puedes saltar porque es opcional para usuarios avanzados. Puedes pasar directamente al apartado Training.
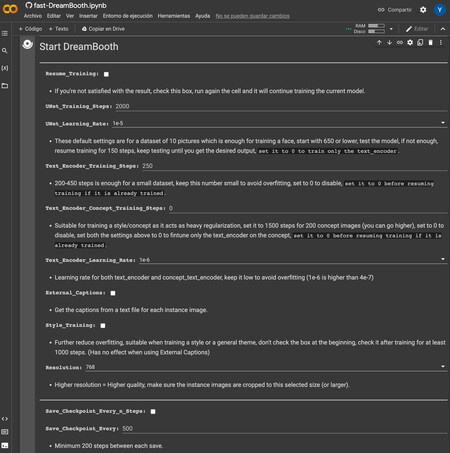
El apartado Training es lo más importante, y significa que vamos a empezar a entrenar a nuestra IA con las imágenes que hemos subido. La mayoría de campos es mejor dejarlos como están, pero te diremos algunas cosas que conviene que cambies dependiendo de lo que vayas a hacer.
Resume_Training: En el caso de que hayas entrenado ya a la IA y no estés satisfecho con el resultado, puedes marcar esto para seguir entrenándola durante unos cuantos pasos más tras cargar la sesión. Solo márcalo si ya la has entrenado una vez y quieres añadir pasos adicionales.UNet_Training_StepsyUNet_Learning_Rate: Son los pasos y el tipo de entrenamiento de la IA. El creador establece 650 pasos por cada 10 imágenes cuando usas el modelo 1e- que aparece por defecto, y que no deberías modificar si no sabes nada. Simplemente, adapta la cantidad a tu número de imágenes.Resolution: Cambia la resolución a la que estamos usando de 768.Save_Checkpoint_Every_n_Steps: Esto es opcional, para que se vayan guardando los cambios a cada determinados pasos por si hay algún fallo.Disconnect_after_training: Si quieres desconectarlo todo después de entrenar. Si no quieres hacer más cambios después del entrenamiento, puedes marcarlo
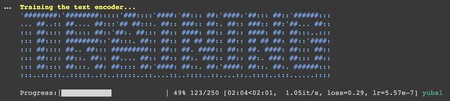
Una vez tengas todo hecho, pulsa en el botón de ejecutar de Start DreamBooth. Este proceso te puede durar bastante tiempo, incluso varias horas.

Turno para el cuaderno de Stable Diffusion
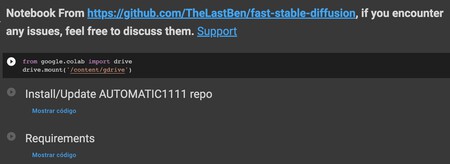
Una vez hayamos hecho el entrenamiento, es turno de empezar a utilizar los resultados y generar los avatares. Para eso, vamos a utilizar el cuaderno de Stable Diffusion 2.1 del proyecto AUTOMATIC1111, que es una interfaz web para usar Stable Diffusion. En él, ve ejecutando las primeras celdas para vincular la misma cuenta de Drive que hayas usado antes. Tras ejecutar ese primer elemento, ejecuta también Install/Update AUTOMATIC1111 repo y Requirements.
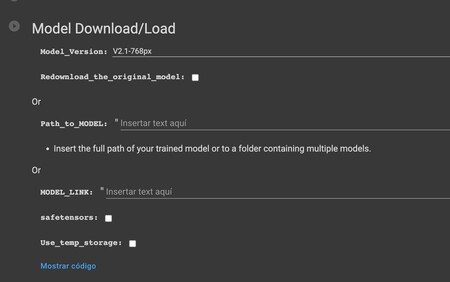
A continuación, en Model Download/Load tienes que elegir la opción v2.1-768, ya que es la misma que hemos utilizado en el punto anterior. Tras hacerlo, deja lo demás como está y ejecuta la celda.
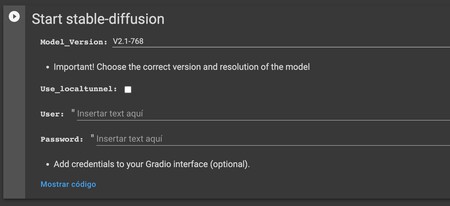
Ahora, llegarás al último paso llamado Start stable-diffusion, que sirve para lanzar Stable Diffusion. En él, en Model_Version vuelve a elegir la opción v2.1-768 o las que hayas usado, deja todo lo demás como está, y ejecuta también esta celda para ejecutar Stable Diffusion.
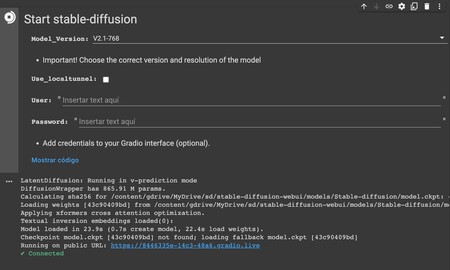
Cuando termine, abajo del todo de la última celda verás el mensaje Running on public URL: seguido de una dirección. Tienes que pulsar en esa URL para entrar en Stable Diffusion ejecutado desde tu Drive.

Mueve el modelo entrenado a la carpeta de Stable Diffusion
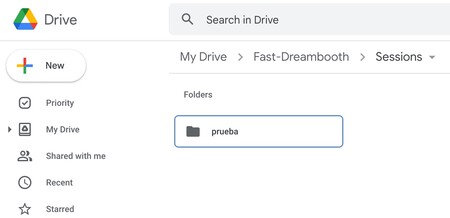
Antes de empezar a usar Stable Diffusion, tienes que ir a la página de Google Drive e iniciar sesión con la cuenta que hayas estado utilizando. Una vez dentro ve a la carpeta Fast-Dreambooth, y entra a Sessions, entrando después a la carpeta con el nombre de la sesión que has creado antes.
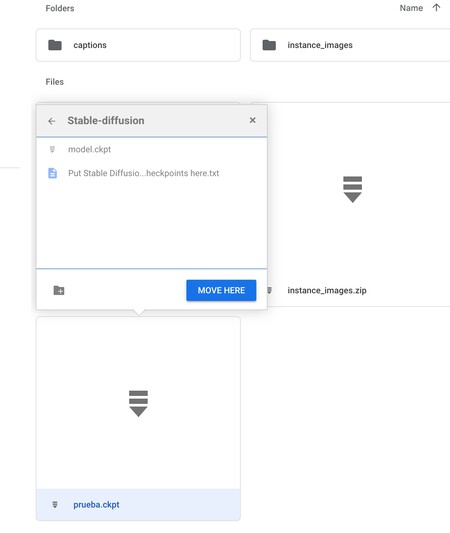
Aquí dentro tendrás un archivo .ckpt, que es donde se ha guardado el modelo de IA entrenado. Lo que tienes que hacer es clic derecho sobre él, y elegir la opción de Mover a. Ahora, tendrás que ir a la raíz de tu Drive, y entrar en sd > stable-diffusion-webui > models > Stable-diffusion y pulsa en Mover aquí. Cuando guardes aquí el archivo .ckpt, estarás guardando tu modelo entrenado en la aplicación creada dentro de Google Drive de Stable Diffusion.
Ahora genera tu avatar
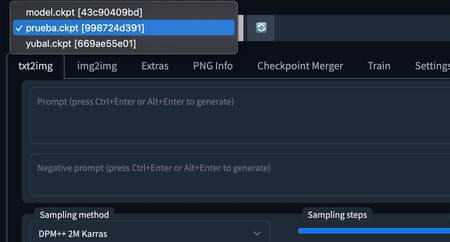
Ahora ya puedes ir a la pestaña donde hayas ejecutado Stable Diffusion en su interfaz web, y arriba del todo abre la pestaña Stable Diffusion checkpoint arriba a la izquierda para seleccionar el modelo que acabamos de mover en el paso anterior. Si no aparece porque lo habías abierto antes de mover la carpeta, pulsa en el botón azul de actualizar para que aparezca. Cargar el modelo puede tardar unos cuantos minutos, ten paciencia.
Ahora, simplemente ve a la pestaña txt2img, que es la de generar una imagen a través de texto. En ella, tienes que escribir el Prompt o comando para generar la imagen. Esta es la parte que más tiempo te va a costar afinar, y donde vas a tener que practicar a partir de ahora.
Realmente, la parte complicada empieza ahora. Lo único que tienes que tener en cuenta es que para que utilice tu cara, debes mencionar el nombre que hubieras puesto en tus fotos. Por ejemplo, para una retrato mío solo tengo que poner portrait of yubal. Y solo con eso ya generará algo.
Y a partir de aquí ya depende todo de ti. La verdadera aventura comienza ahora, porque encontrar un prompt que genere una imagen tal y como tú la quieres puede ser complicado. Puedes empezar explorando, y poco a poco ir añadiendo más detalles a tu petición. También puedes buscar los prompts para Stable Diffusion en Internet, aunque los buenos suelen incluso ser de pago.
Esto ves así porque la parte más complicada de crear imágenes a través de IA es el comando de petición o prompt que le envías a la IA. Aplicaciones como Lensa se diferencian de todas las demás por los prompts que usan, y este es el auténtico tesoro a la hora de generar imágenes.

Aquí solo recordarte que los comandos los puedes poner también en español. En mi caso, después de copiar y pegar algunos prompts de Internet empecé a buscar combinaciones por mi cuenta. Empecé con «retrato de yubal», luego pasé a «retrato de yubal, pintado por van gogh», y así poco a poco fui añadiéndole elementos separándonos por una coma.
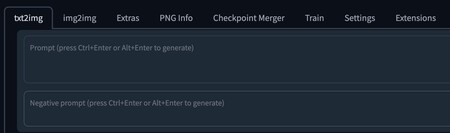
Además del campo de Prompt, también tienes uno de Negative Prompts por si quieres añadir defectos a la imagen, ya sea arrugas, roturas, lo que quieras.
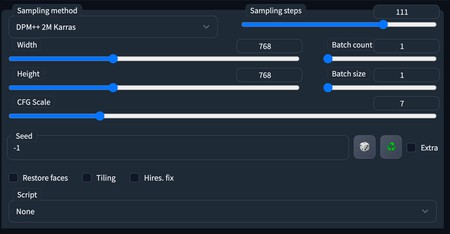
Además de el prompt, verás que debajo tienes otros elementos con los que puedes configurar la imagen. Aquí lo que elijas determinará también el resultado, pudiendo determinar el método de sampleo, que le da diferentes estilos al dibujo. Lo único importante de cambiar es width y height, la anchura y altura de la imagen, que deben ser de 768 por haber entrenado a la IA con estos tamaño.
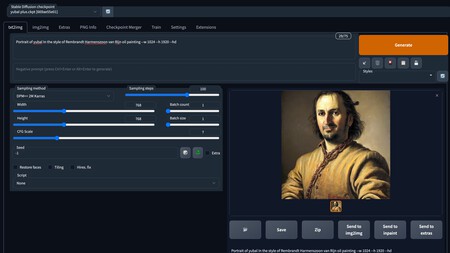
Lo demás, lo mejor es que vayas explorando. Otra cosa importante es el campo Sampling steps, que son los pasos que da la IA para crear la imagen. Cuantos más pasos, más detalles y precisión tendrá la imagen, aunque un poco menos de creatividad. Lo recomendable es tenerlo a 50, pero puedes ir cambiándolo de vez en cuando para explorar resultados. Cada vez que generes una imagen será diferente, incluso si repites la misma configuración y prompt.
Para terminar, cabe la posibilidad de que a veces algunos de estos cuadernos den fallos temporales, ya que el código del que están compuestos tiene muchas variantes y son proyectos colaborativos en los que alguien toca una cosa en un sitio y todo lo demás puede fallar. Si te encuentras con que el cuaderno para entrenar a la IA no funciona o que el generador de imágenes de Stable Diffusion hace cosas raras, lo normal es que el problema se solucione en pocas horas.


