
Ada Lovelace era inteligente, ambiciosa, apasionada, curiosa… A mediados del siglo pasado, cien años después de su muerte, varios investigadores descubrieron su trabajo y una colección de aportaciones que décadas más tarde resultaron muy valiosas para el desarrollo de la informática y la programación. La relevancia histórica de esta visionaria es indudable, de ahí que NVIDIA haya decidido homenajearla poniendo su nombre a la arquitectura de su familia de GPU GeForce RTX 40.
El propósito de este artículo es indagar en las muchas novedades introducidas por los ingenieros de NVIDIA en estos nuevos procesadores gráficos, pero antes de meternos en harina merece la pena que recapitulemos. Las primeras tarjetas gráficas pertenecientes a la serie GeForce RTX 40 que llegarán a las tiendas serán la RTX 4090 y las RTX 4080. Y es que, sorprendentemente, NVIDIA ha decidido lanzar dos versiones diferentes de esta última solución gráfica.
Una de las RTX 4080 incorpora 16 GB de VRAM de tipo GDDR6X, y la otra 12 GB de este mismo tipo de memoria. No obstante, las diferencias entre estas dos tarjetas gráficas no acaban aquí. Y es que su GPU no rinde igual, y su bus de memoria es diferente. En la tabla que publicamos debajo de estas líneas recogemos estas diferencias. Otro dato interesante más: Samsung ya no fabrica estas GPU para NVIDIA. Las RTX 40 las produce TSMC utilizando su nodo litográfico de 4 nm.
Las GeForce RTX 4090 y 4080 frente a las GeForce RTX 3090 Ti y 3080 Ti
|
nvidia geforce rtx 4090 |
nvidia geforce rtx 3090 ti |
nvidia geforce rtx 4080 |
NVIDIA GEFORCE RTX 3080 TI |
|
|---|---|---|---|---|
|
arquitectura |
Ada Lovelace |
Ampere |
Ada Lovelace |
Ampere |
|
transistores |
76 000 millones |
28 300 millones |
No disponible |
28 300 millones |
|
fotolitografía |
4 nm TSMC |
8 nm Samsung (tecnología de integración personalizada para NVIDIA) |
4 nm TSMC |
8 nm Samsung (tecnología de integración personalizada para NVIDIA) |
|
núcleos cuda |
16 384 |
10 752 |
9728 (16 GB) 7680 (12 GB) |
10 240 |
|
núcleos rt |
128 (3ª generación) |
84 (2ª generación) |
76 (3ª generación) |
80 (2ª generación) |
|
núcleos tensor |
512 (4ª generación) |
336 (3ª generación) |
304 (4ª generación) |
320 (3ª generación) |
|
unidades de cálculo (cu) |
128 |
84 |
76 |
80 |
|
caché de nivel 1 |
128 Kbytes (por SM) |
128 Kbytes (por SM) |
128 Kbytes (por SM) |
128 Kbytes (por SM) |
|
frecuencia de reloj máxima |
2,52 GHz |
1,86 GHz |
2,51 GHz (16 GB) 2,61 GHz (12 GB) |
1,67 GHz |
|
memoria dedicada |
24 GB GDDR6X |
24 GB GDDR6X |
16 GB GDDR6X o 12 GB GDDR6X |
12 GB GDDR6X |
|
bus de memoria |
384 bits |
384 bits |
256 bits (16 GB) 192 bits (12 GB) |
384 bits |
|
velocidad de transferencia de la memoria |
1008 GB/s |
1008 GB/s |
735 GB/s (16 GB) |
912 GB/s |
|
shader tflops (fp32) |
90 |
40 |
49 |
34 |
|
operaciones de rasterización |
192 ROP/s |
112 ROP/s |
96 ROP/s |
112 ROP/s |
|
unidades de mapas de texturas |
512 |
336 |
304 |
320 |
|
tasa de texturas |
1290 Gtexeles/s |
625 Gtexeles/s |
761,5 Gtexeles/s |
532,8 Gtexeles/s |
|
tasa de píxeles |
483,8 Gpíxeles/s |
208,3 Gpíxeles/s |
240,5 Gpíxeles/s |
186,5 Gpíxeles/s |
|
directx 12 ultimate |
Sí |
Sí |
Sí |
Sí |
|
interfaz pci express |
PCIe 4.0 |
PCIe 4.0 |
PCIe 4.0 |
PCIe 4.0 |
|
revisión hdmi |
2.1 |
2.1 |
2.1 |
2.1 |
|
revisión displayport |
1.4a |
1.4a |
1.4a |
1.4a |
|
dlss |
3 |
2 |
3 |
2 |
|
ranuras ocupadas |
3 |
3 |
3 (16 GB) 2 o 3 (12 GB) |
2 |
|
temperatura máxima de la gpu |
90 ºC |
92 ºC |
90 ºC |
93 ºC |
|
consumo medio |
450 vatios |
450 vatios |
320 vatios |
350 vatios |
|
potencia recomendada para la fuente de alimentación |
850 vatios |
850 vatios |
750 vatios |
750 vatios |
|
conectores de alimentación |
3 x 8 pines o 1 cable PCIe Gen 5 de 450 vatios o más |
3 x 8 pines |
16 GB: 3 x 8 pines o 1 cable PCIe Gen 5 de 450 vatios o más 12 GB: 2 x 8 pines o 1 cable PCIe Gen 5 de 300 vatios o más |
2 x 8 pines |
|
precio |
Desde 1959 euros |
Desde 1469 euros (16 GB) Desde 1099 euros (12 GB) |
La arquitectura Ada Lovelace de las GeForce RTX 40, bajo nuestra lupa
NVIDIA no se ha andado con delicadezas a la hora de comunicar qué representa para esta compañía la llegada de la arquitectura Ada Lovelace: un salto gigantesco en términos de rendimiento y eficiencia. Suena bien, de eso no cabe la menor duda, pero dado que esta afirmación procede de una parte interesada lo más prudente es que la recojamos con cierto escepticismo hasta que tengamos la oportunidad de analizar a fondo una de las nuevas tarjetas gráficas GeForce RTX 40.
En cualquier caso, más allá de la apuesta por la tecnología de integración de 4 nm de TSMC en detrimento de la litografía de 8 nm de Samsung utilizada en la fabricación de los procesadores gráficos GeForce RTX 30, las nuevas GPU de NVIDIA nos entregan una nueva generación de núcleos RT y núcleos Tensor, así como más núcleos CUDA que nunca. También llegan de la mano de frecuencias de reloj más altas e implementan tecnologías de procesado de la imagen más sofisticadas. Así se las gastan las brutales (y caras) GeForce RTX 40.
Más núcleos CUDA, y, además, llegan los núcleos RT de 3ª generación
Los núcleos CUDA se responsabilizan de llevar a cabo los cálculos complejos a los que se enfrenta una GPU para resolver, entre otras tareas, la iluminación general, el sombreado, la eliminación de los bordes dentados o la física. Estos algoritmos se benefician de una arquitectura que prioriza el paralelismo masivo, por lo que cada nueva generación de GPU de NVIDIA incorpora más núcleos CUDA.
La arquitectura de los núcleos CUDA prioriza el paralelismo masivo, de ahí que cada nueva generación de GPU de NVIDIA incorpore más unidades de este tipo
Como cabía esperar, los procesadores gráficos de la familia GeForce RTX 40 tienen muchos más núcleos de este tipo que sus predecesores. De hecho, la GPU GeForce RTX 4090 incorpora 16 384 núcleos CUDA, mientras que la GeForce RTX 3090 Ti se conforma con 10 752. La GeForce RTX 4080 de 16 GB tiene 9728, y la versión de 12 GB incorpora 7680 núcleos CUDA. La GeForce RTX 3080 Ti las supera a ambas con sus 10 240 núcleos de este tipo, pero la RTX 3080 se coloca entre las dos versiones de la RTX 4080 con sus 8704 núcleos CUDA.

Los núcleos RT (Ray Tracing), por otro lado, son las unidades que se encargan expresamente de asumir una gran parte del esfuerzo de cálculo que requiere el renderizado de las imágenes mediante trazado de rayos, liberando de este estrés a otras unidades funcionales de la GPU que no son capaces de llevar a cabo este trabajo de una forma tan eficiente. Son en gran medida responsables de que las tarjetas gráficas de las series GeForce RTX 20, 30 y 40 sean capaces de ofrecernos ray tracing en tiempo real.
NVIDIA asegura que sus núcleos RT de 3ª generación duplican el rendimiento de sus predecesores al procesar las intersecciones de los triángulos
NVIDIA asegura que sus núcleos RT de 3ª generación duplican el rendimiento de sus predecesores al procesar las intersecciones de los triángulos que intervienen en el renderizado de cada fotograma. Además, estos núcleos incorporan dos nuevos motores conocidos como Opacity Micromap (OMM), o ‘micromapa de opacidades’, y Displaced Micro-Mesh (DMM), que podemos traducir como ‘micromalla de desplazamientos’.
Dejando a un lado los detalles más complejos, el motor OMM tiene el propósito de acelerar el renderizado mediante trazado de rayos de las texturas empleadas en la vegetación, las vallas y las partículas. El procesado de estos tres elementos representa un gran esfuerzo para la GPU, y el objetivo de este motor es, precisamente, aliviarlo. Por otro lado, el motor DMM se encarga de procesar las escenas que contienen una gran complejidad geométrica para hacer posible el renderizado en tiempo real mediante trazado de rayos.
Los núcleos Tensor evolucionan: llega la 4ª generación
Al igual que los núcleos RT, los núcleos Tensor son unidades funcionales de hardware especializadas en resolver operaciones matriciales que admiten una gran paralelización, pero estos últimos han sido diseñados expresamente para ejecutar de forma eficiente las operaciones que requieren los algoritmos de aprendizaje profundo y la computación de alto rendimiento. Los núcleos Tensor ejercen un rol esencial en la tecnología DLSS (Deep Learning Super Sampling), de ahí que tengan un claro protagonismo en la reconstrucción de la imagen mediante DLSS 3.

Según NVIDIA, la 4ª iteración de estos núcleos es mucho más rápida que su predecesora, logrando multiplicar su rendimiento por cinco en determinadas circunstancias. Un apunte interesante: el motor de transformación FP8 utilizado por primera vez por esta marca en estos núcleos para llevar a cabo cálculos con números en coma flotante de 8 bits procede de la GPU H100 Tensor Core diseñada por NVIDIA expresamente para los centros de datos que trabajan con algoritmos de inteligencia artificial.
Estas dos tecnologías nos prometen marcar la diferencia en las GeForce RTX 40
El esfuerzo computacional que conlleva el renderizado en tiempo real de un fotograma mediante trazado de rayos es descomunal. Esta es la razón por la que cada nueva generación de procesadores gráficos no puede conformarse únicamente con introducir una cantidad mayor de las mismas unidades funcionales presentes en sus predecesoras.
La fuerza bruta importa, pero no es suficiente en absoluto. También es imprescindible elaborar estrategias que consigan abordar los procesos involucrados en el renderizado de una forma más inteligente. Más ingeniosa.
Las tecnologías ‘Shader Execution Reordering’ y ‘Ada Optical Flow Accelerator’ persiguen incrementar el rendimiento de la GPU abordando las tareas involucradas en el renderizado de la forma más eficiente posible
Este es el enfoque que pone sobre la mesa NVIDIA con las GPU GeForce RTX 40, y a nosotros nos parece la opción correcta. Precisamente las dos tecnologías en las que estamos a punto de indagar, conocidas como Shader Execution Reordering (SER) y Ada Optical Flow Accelerator, persiguen llevar a la práctica este propósito: incrementar el rendimiento de la GPU abordando las tareas involucradas en el renderizado que desencadenan un mayor esfuerzo computacional de la forma más eficiente posible.
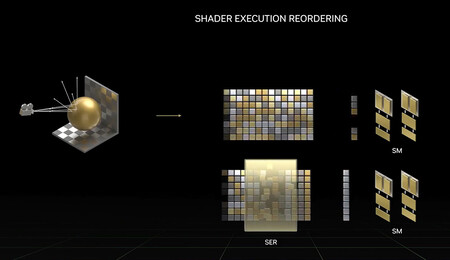
La tecnología Shader Execution Reordering (SER) se responsabiliza de optimizar los recursos de la GPU reorganizando en tiempo real y de una manera inteligente los sombreadores (shaders), que son los programas que llevan a cabo los cálculos necesarios para resolver los atributos esenciales del fotograma que se está renderizando, como la iluminación o el color.
De alguna forma esta técnica lleva a cabo un procedimiento similar a la ejecución superescalar de las CPU, lo que, según NVIDIA, permite a la tecnología SER multiplicar por tres el rendimiento del renderizado mediante trazado de rayos, incrementando, por el camino, la cadencia de imágenes por segundo en hasta un 25%. No pinta nada mal.
Por otro lado, la tecnología Ada Optical Flow Accelerator tiene el propósito de predecir qué objetos se van a desplazar entre dos fotogramas consecutivos para entregar esa información a la red neuronal convolucional involucrada en la reconstrucción de la imagen mediante DLSS 3.
Según NVIDIA esta estrategia multiplica por dos el rendimiento de la anterior implementación de la tecnología DLSS, y, a la par, mantiene intacta la calidad de imagen. De nuevo, suena muy bien, pero los usuarios tendremos que ir comprobando poco a poco si realmente esta innovación está a la altura de las expectativas que está generando.
NVIDIA nos promete que las GeForce RTX 40 son más eficientes que las RTX 30
Una de las consecuencias de la adopción de la tecnología de integración de 4 nm de TSMC frente a la litografía de 8 nm utilizada por Samsung para fabricar las GPU de la familia GeForce RTX 30 consiste en que los últimos procesadores gráficos de NVIDIA deberían ser perceptiblemente más eficientes. Y sí, eso es precisamente lo que nos promete esta marca.

Según NVIDIA la temperatura máxima que alcanzan bajo estrés las GPU GeForce RTX 4090 y 4080 asciende a 90 ºC
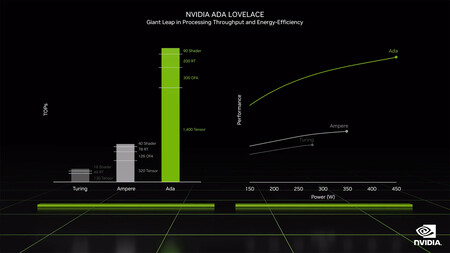
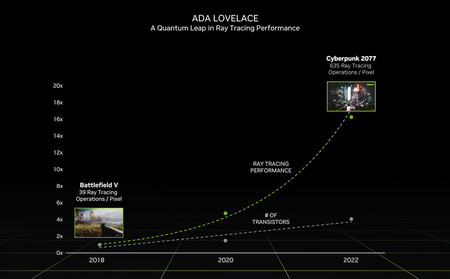
La diapositiva que publicamos debajo de estas líneas describe la relación que existe entre la energía consumida y el rendimiento que nos entregan las GPU con arquitectura Turing, Ampere y Ada Lovelace. Y, efectivamente, esta última implementación gana por goleada a sus predecesoras. Aun así, no debemos pasar por alto las exigencias de las nuevas tarjetas gráficas de NVIDIA si nos ceñimos a su consumo eléctrico.
Según NVIDIA la temperatura máxima que alcanzan bajo estrés las GPU GeForce RTX 4090 y 4080 asciende a 90 ºC, pero el consumo medio de la RTX 4090 roza los 450 vatios, mientras que la RTX 4080 coquetea con los 320 vatios. Por otro lado, NVIDIA sugiere que los equipos en los que va a ser instalada una RTX 4090 cuenten con una fuente de alimentación de 850 vatios o más, mientras que la RTX 4080 requiere una fuente de al menos 750 vatios.
DLSS 3 multiplica por cuatro el rendimiento con ‘ray tracing’
La técnica de reconstrucción de la imagen empleada por NVIDIA recurre al análisis en tiempo real de los fotogramas de nuestros juegos utilizando algoritmos de aprendizaje profundo. Su estrategia es similar a la que emplean otros fabricantes de hardware gráfico: la resolución de renderizado es inferior a la resolución de salida que finalmente entrega la tarjeta gráfica a nuestro monitor.
El motor gráfico renderiza las imágenes a una resolución inferior a la que esperamos obtener, y después la tecnología DLSS escala cada fotograma a la resolución final
De esta forma el estrés al que se ve sometido el procesador gráfico es menor, pero a cambio es necesario recurrir a un procedimiento que se encargue de escalar cada uno de los fotogramas desde la resolución de renderizado hasta la resolución final. Y, además, debe hacerlo de una forma eficiente porque, de lo contrario, el esfuerzo que hemos evitado en la etapa anterior podría aparecer en esta fase de la generación de las imágenes.
Esta es la fase en la que entra en acción la inteligencia artificial que ha puesto a punto NVIDIA. Y los núcleos Tensor de la GPU. El motor gráfico renderiza las imágenes a una resolución inferior a la que esperamos obtener, y después la tecnología DLSS escala cada fotograma a la resolución final aplicando una técnica de muestreo mediante aprendizaje profundo para intentar recuperar el máximo nivel de detalle posible.
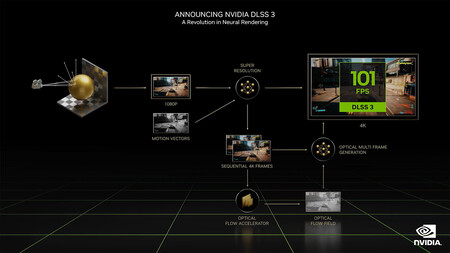
En las imágenes que hemos utilizado para ilustrar este artículo podemos ver que el procedimiento implementado en DLSS 3 es más complejo que el utilizado por DLSS 2. De hecho, la nueva técnica de reconstrucción de la imagen de NVIDIA aprovecha la presencia de los núcleos Tensor de cuarta generación de las GPU GeForce RTX 40 para hacer posible la ejecución de un nuevo algoritmo de reconstrucción llamado Optical Multi Frame Generation.
‘Optical Multi Frame Generation’ analiza dos imágenes secuenciales del juego en tiempo real y calcula la información del vector que describe el movimiento de todos los objetos
En vez de abordar la reconstrucción de cada fotograma trabajando con píxeles aislados, que es lo que hace DLSS 2, esta estrategia genera fotogramas completos. Para hacerlo analiza dos imágenes secuenciales del juego en tiempo real y calcula la información del vector que describe el movimiento de todos los objetos que aparecen en esos fotogramas, pero que no son procesados por el motor del propio juego.
Según NVIDIA esta técnica de reconstrucción de la imagen consigue multiplicar por cuatro la cadencia de imágenes por segundo que nos entrega DLSS 2. Y, lo que también es muy importante, minimiza las aberraciones y las anomalías visuales que aparecen en algunos juegos al utilizar la anterior revisión de esta estrategia de reconstrucción de la imagen. Suena muy bien, así que estamos deseando probarla para comprobar si su rendimiento es tan atractivo como nos está prometiendo NVIDIA.
El procesado de los fotogramas en alta resolución y los vectores de movimiento se alimentan de una red neuronal convolucional
Un apunte interesante más: el procesado de los fotogramas en alta resolución y los vectores de movimiento se alimentan, según nos explica NVIDIA, de una red neuronal convolucional que analiza toda esta información y genera en tiempo real un frame adicional por cada fotograma procesado por el motor del juego.
Para concluir, ahí va otra promesa de esta compañía: DLSS 3 puede trabajar en tándem con Unity y Unreal Engine, y durante los próximos meses llegará a más de 35 juegos. De hecho, es posible habilitar esta técnica en poco tiempo en aquellos títulos que ya implementan DLSS 2 o Streamline.


